In the first part I gave a general overview of the protocol, and how it unfolds for the base case. As it turns out, implementing pBFT even for non-production scenarios is not a one-evening project. This post outlines the assumptions, and decisions I have made for the implementation, together with the general structure of the project and some more interesting parts.
NOTE: Since the whole code base became a bit too big, after several attempts I decided to make this article more of an overview than a very detailed write-up. I hope it gives enough of a background to allow anyone interested to find their way through the codebase.
Implementation Assumptions
To have something to base the implementation on I had to make some decisions on what to build and how, that are not strictly related to the protocol. The aim was to keep things “fairly” complete but with a bias towards simplicity. With this in mind, I settled on the following:
The application itself is a simple Key-Value store.
All communication is done through HTTP with messages in JSON format.
There is only one binary exposing both Key Value service as well as internal pBFT endpoints – in a real-world project it would be good to separate them so that the consensus layer could handle different end-user applications.
Core pBFT logic, however, is separated from pbft-core library.
Message authentication is done with Ed25519 signatures
Other replicas, their addresses, and public keys are distributed as a configuration file (for development a built-in config can be used to quickly spin up nodes locally).
Key-Value store and pBFT clients are not authenticated in any way.
Who is the client?
To avoid confusion early on, let’s set things straight. There will be a notion of two different clients in our system:
The client from pBFT perspective (what paper refers to as “client”) – In this section I will refer to it as pbft-client, but later anytime I mention “client”, think pbft-client.
The client who uses the Key-Value Store – I will refer to it as kv-client.
What is all that about?
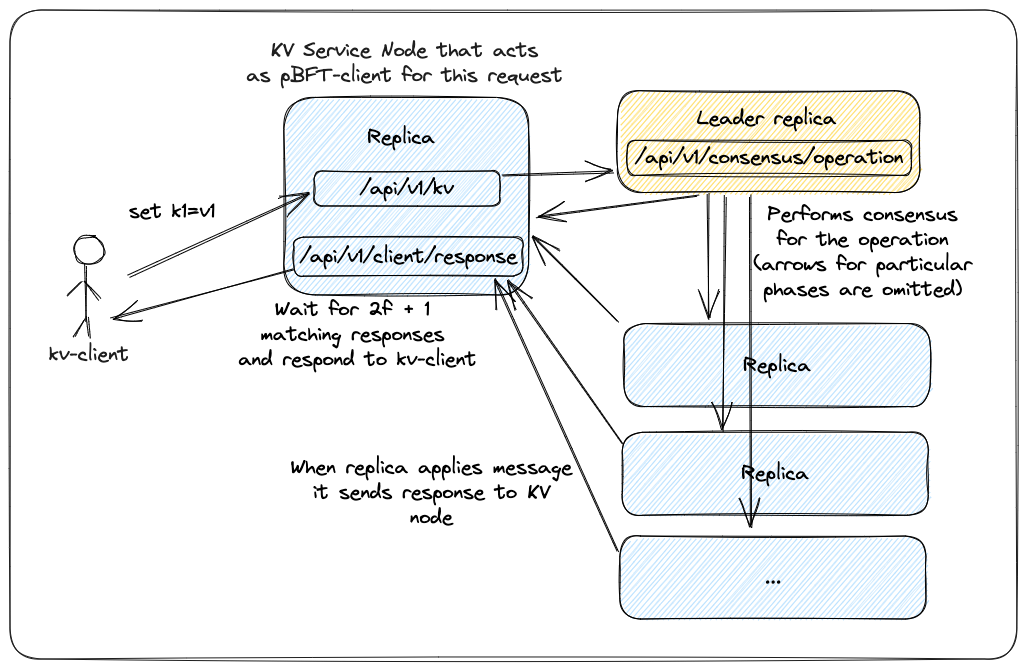
In our case, the client of the consensus layer (pbft-client) will actually be the Key-Value (KV) Service itself, as it is going to translate kv-client requests into pBFT operation and send them to pBFT leader. Because of that the KV Service will also expose an endpoint to which pBFT replicas are going to send their responses. When it gathers enough confirmations that the request was executed, it will respond to the kv-client with the result.
KV-client and pBFT-client response flow
The main reasons for such an implementation are:
Shift complexity to the backend (KV Service).
kv-client can be oblivious to the consensus mechanism that is going on behind the scenes.
pbft-client needs to be reachable by all pBFT nodes, so it is easier if it is a server listening for connections on some port.
With this (hopefully) clear, we can do a quick tour through the implementation.
Project Overview
PBFT State
The hearth of our pBFT node is the PbftState. It is going to store anything from the current replica state, and the sequence number of the last applied message, to all ClientRequest and ProtocolMessages. For our implementation all of it will live in memory, however, in the real-world scenario this would need to be backed by persistent storage.
pubenumReplicaState{Replica,Leader{sequence: u64},ViewChange,}pubstructPbftState{pub(crate)replica_state: ReplicaState,pub(crate)view: u64,pub(crate)high_watermark: u64,pub(crate)low_watermark: u64,/// watermark_k defines the range between low and high watermarks
pub(crate)watermark_k: u64,pub(crate)last_applied_seq: u64,pub(crate)message_store: MessageStore,pub(crate)consensus_log: ConsensusLog,pub(crate)checkpoint_log: CheckpointLog,pub(crate)view_change_log: ViewChangeLog,pub(crate)timer: Option<ViewChangeTimer>,// We are going to store checkpoints in JSON format so that we can easily
// take digest of them. In a real system, they would also not live in memory
// but rather be stored on disk. Also for that reason we separate
// checkpoints and their digests.
pub(crate)checkpoints: BTreeMap<u64,String>,pub(crate)checkpoint_digests: BTreeMap<u64,CheckpointDigest>,}
Logs where we store different ProtocolMessages are BTreeMaps so that we can easily iterate over them in order determined by either a sequence number, view number, or both combined into ConsensusLogIdx.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
/// ConsensusLog is a map of a combination of view and sequence numbers. It
/// determines a state of a consensus for a specific request.
typeConsensusLog=BTreeMap<ConsensusLogIdx,RequestConsensusState>;/// ViewChangeLog is a map of view number to a list of view change messages
typeViewChangeLog=BTreeMap<u64,Vec<SignedViewChange>>;/// ConsensusLog is a map of sequence number to a checkpoint consensus state.
/// It keeps track of Checkpoint messages for specific sequence numbers.
typeCheckpointLog=BTreeMap<u64,CheckpointConsensusState>;...pubstructConsensusLogIdx{pubview: u64,pubsequence: u64,}...
The last crucial part is RequestConsensusState which is going to store all things necessary for the node to determine where the particular message is in terms of its journey through the protocol. This means PrePrepare, all Prepare, and Commit messages:
1
2
3
4
5
6
7
8
9
10
11
pubstructRequestConsensusState{pubdigest: MessageDigest,pubpre_prepare: Option<SignedPrePrepare>,pubprepare: Vec<SignedPrepare>,pubcommit: Vec<SignedCommit>,// Those will be flipped to true when the state is reached initially, so
// that the replica does not broadcast the same message multiple times.
pubreported_prepared: bool,pubreported_committed_local: bool,}
While PbftState is going to store all the things, PbftExecutor is going to do all the things (or at least a lot of them).
After a few different approaches I settled on the one where the Executor runs an event loop that processes incoming broadcasts, and internal events (e.g. when the view change timer expires), but still handles requests coming from the client directly instead of putting them into the queue. This choice requires us to use Mutex for the PbftState (which we could avoid if running a single event loop) but simplifies the API by not making it asynchronous.
pubstructEventOccurance{pubevent: Event,pubattempt: u32,}pubtypeEventQueue=tokio::sync::mpsc::Sender<EventOccurance>;pubstructPbftExecutor{event_tx: EventQueue,// HACK: We wrap event_rx in Mutex<Option<...>> so that we we can swap it
// and take the full ownership of the receiver without mutable referencing
// the Executor itself.
event_rx: Arc<Mutex<Option<tokio::sync::mpsc::Receiver<EventOccurance>>>>,// backup_queue is used if the main queue is full.
// For real system, this could be backed by some persistant storage to ofload
// the memory. Here we are going to simply use unbouded channel.
backup_queue: tokio::sync::mpsc::UnboundedSender<EventOccurance>,backup_rx: Arc<Mutex<Option<tokio::sync::mpsc::UnboundedReceiver<EventOccurance>>>>,node_id: NodeId,config: Config,pbft_state: Arc<Mutex<PbftState>>,state_machine: Arc<RwLock<dynStateMachie>>,keypair: Arc<ed25519_dalek::Keypair>,broadcaster: Arc<dynPbftBroadcaster>,}
The Executor’s interface boils down to a few methods:
implPbftExecutor{pubfnhandle_client_request(&self,request: ClientRequest)-> Result<ClientRequestResult>{...}pubfnqueue_protocol_message(&self,sender_id: u64,msg: ProtocolMessage){self.queue_event(Event::ProtocolMessage(NodeId(sender_id),msg).into())}pubfnqueue_request_broadcast(&self,sender_id: u64,msg: ClientRequestBroadcast){self.queue_event(Event::RequestBroadcast(NodeId(sender_id),msg).into())}pubasyncfnrun(&self,mutrx_cancel: tokio::sync::broadcast::Receiver<()>)-> (){// HACK: hack to take full ownership of the receiver without needing a
// mutable reference to the executor itself.
letevent_rx=self.event_rx.lock().unwrap().take();ifevent_rx.is_none(){error!("event channel is not present, cannot start executor event loop");return();}letmutevent_rx=event_rx.unwrap();loop{tokio::select!{_=rx_cancel.recv()=>{info!("received cancel signal");return();}event=event_rx.recv()=>{// Handle event...
}}}}}
and Event is defined as an enum of three variants:
In part one I describe some steps involved in doing those, if you are interested in the implementation, I hope that the links above give a good enough starting point to not get lost. After all, it boils down to doing some validation, adding entries to maps, and checking some conditions.
Configuration
Before we go any further, it is worth looking at the node configuration. Besides some obvious things one may want to tweak without touching the source code like checkpoints frequency or view change timeout, the most important part for the consensus is information about other nodes.
As I briefly mentioned in the assumptions, nodes know about each other from the config, which contains their IDs, addresses, and public keys. self_id determines the ID of this particular node, and private_key_path points to the file containing the private key used for signing messages, which is loaded at the startup.
There is also a response_urls field, which informs our nodes where to send the client response. Since the pbft-client is going to be only the KV Service, I decided to send responses to all KV Nodes every time, as opposed to passing response_url in ClientRequest on a per-request basis. The reasoning behind it is that kv-client may connect to different KV Nodes (as there are no sessions etc.), and hence send the request to one node, but retry it to the other.
Broadcaster
Knowing where the addresses of fellow replicas come from we can look into Broadcaster component. Invoked by the PbftExecutor it handles: broadcasting client requests between the nodes, protocol messages, as well as delivering responses to clients.
The implementation is simple. We create a Future for each request to be sent, put it into FuturesUnordered, and spawn tokio::task to await their execution:
fnsend_client_responses(&self,responses: Vec<ClientResponse>){letmutfuts=FuturesUnordered::new();forrespinresponses{forurlin&self.response_urls{letclient=self.client.clone();letself_id=self.node_self_id;letkeypair=self.keypair.clone();letresp=resp.clone();leturl=url.clone();futs.push(Box::pin(asyncmove{Broadcaster::send_with_retires(client,self_id,&keypair,&resp,url.as_str()).await}));}}tokio::spawn(asyncmove{whileletSome(out)=futs.next().await{matchout{Ok(_)=>{}Err(err)=>{error!(error=?err,"failed to send response to client in all attempts");}}}});}
It is not ideal in way that our pBFT code does not know if the request was received successfully, but allows us to keep the method non-async, and therefore not spread it throughout the whole codebase.
NOTE: A better implementation here could be to create a request queue, and make broadcaster distribute requests over a pool of workers. This would allow us to better keep track of what is going on, have sane limits, and retry policy… but I did not implement it.
There are a few more things going on in the Broadcaster, but probably the most important one is signing messages.
When sending the message, the Broadcaster serializes the payload to JSON, and signs it with the replica private key. Then it adds two headers to the request, one containing Replica ID, and the other hex-encoded signature. This way other replicas can later easily find the public key to verify the signature.
It is just a simple map, so there is nothing really to talk about. In case you want to check it out the source code is very simple.
API
Now that we have covered the core components implementing the pBFT let’s take a peek at an API. Since it is an entrypoint to the application it has to wrap nicely around the protocol to make it usable.
As I have mentioned in the first part, for simplicity both the application and consensus layer will be a part of a single application, and therefore API as well. Paths for different responsibilities are going to be grouped, but it all will run as a single server. We can quickly glimpse at routes configuration, to get a better idea (for details see api.rs in kv-node).
letkv_router=Router::new().route("/",post(handle_kv_set)).route("/",get(handle_kv_get)).route("/local",get(handle_kv_get_local));// KV Nodes receives responses from pBFT replicas here
letconsensus_client_router=Router::new().route("/response",post(handle_client_consensus_response));// KV Node translates the request to pBFT operation and sends it here
letconsensus_ext_router=Router::new()// Request operation to execute
.route("/operation",post(handle_consensus_operation_execute));// pBFT nodes talking to each other
letconsensus_int_router=Router::new()// Client Request + PrePrepare broadcasted by the leader
.route("/execute",post(handle_consensus_pre_prepare))// Any other consensus message -- Prepare, Commit, ViewChange, NewView
.route("/message",post(handle_consensus_message))// Debuging endpoint to dump current pBFT state
.route("/state",get(handle_state_dump));// Combine routers
letapp=Router::new().route("/api/v1/health",get(health_handler)).nest("/api/v1/kv",kv_router).nest("/api/v1/client",consensus_client_router).nest("/api/v1/consensus",consensus_ext_router).nest("/api/v1/pbft",consensus_int_router).with_state(self.ctx.clone());
The other important part of the API is verifying that the request comes from the replica it claims to. We have looked at how the Broadcaster signs the request body and adds two headers to the request. Now it is the time to do the reverse. With custom axum extractor the node verifies the signature prior to deserializing JSON body to whatever type the handler expects:
pubstructJsonAuthenticated<T: DeserializeOwned>{pubsender_id: u64,pubdata: T,}pubstructJsonAuthenticatedExt<T: DeserializeOwned>(pubJsonAuthenticated<T>);#[async_trait]impl<S,T: DeserializeOwned>FromRequest<S,Body>forJsonAuthenticatedExt<T>whereS: VerifySignrature+Send+Sync,{typeRejection=axum::response::Response;asyncfnfrom_request(req: axum::http::Request<Body>,state: &S,)-> Result<Self,Self::Rejection>{let(parts,body)=req.into_parts();letsignature=get_replica_signature(&parts.headers)?;letpeer_id=get_sender_replica_id(&parts.headers)?;// this wont work if the body is an long running stream -- it is fine
letbytes=hyper::body::to_bytes(body).await.map_err(|err|(StatusCode::INTERNAL_SERVER_ERROR,err.to_string()).into_response())?;state.verify_signature(peer_id,&signature,&bytes)?;letdata=serde_json::from_slice(&bytes).map_err(|err|(StatusCode::BAD_REQUEST,err.to_string()).into_response())?;Ok(JsonAuthenticatedExt(JsonAuthenticated{sender_id: peer_id,data: data,}))}}
Verifying the signature boils down to hex-decoding public key and the signature, and doing the verification:
pubfnverify_request_signature(&self,replica_id: u64,signature: &str,msg: &[u8],)-> Result<(),crate::error::Error>{ifreplica_id>self.nodes_config.nodes.len()asu64{returnErr(crate::error::Error::InvalidReplicaID{replica_id: NodeId(replica_id),});}letpeer=&self.nodes_config.nodes[replica_idasusize];letpub_key_raw=hex::decode(peer.public_key.as_bytes()).map_err(crate::error::Error::hex_error("failed to decode public key from hex"),)?;letpublic_key=PublicKey::from_bytes(&pub_key_raw).map_err(crate::error::Error::ed25519_error("failed to parse public key from bytes"),)?;letsignature_raw=hex::decode(signature.as_bytes()).map_err(crate::error::Error::hex_error("failed to decode signature from hex"),)?;letsignature=Signature::from_bytes(&signature_raw).map_err(crate::error::Error::ed25519_error("failed to parse signature from bytes"),)?;letis_ok=public_key.verify(msg,&signature).is_ok();if!is_ok{returnErr(crate::error::Error::InvalidSignature);}Ok(())}
Now we simply use the extractor for the handlers where we want to verify the signature. If the message is not signed, or the signature is not right, the request is rejected before we reach the handler:
This covers the main components of the application, the rest “is just” protocol implementation… The last part is going to look into the remaining parts of the protocol that I did not touch on yet such as checkpoints and the view change.